IDEA创建Maven项目时 loading archetype list转菊花转十年解决方案
本文共 651 字,大约阅读时间需要 2 分钟。
在使用IDEA创建Maven项目时,遇到 loading archetype list一直转菊花的问题,如下图:
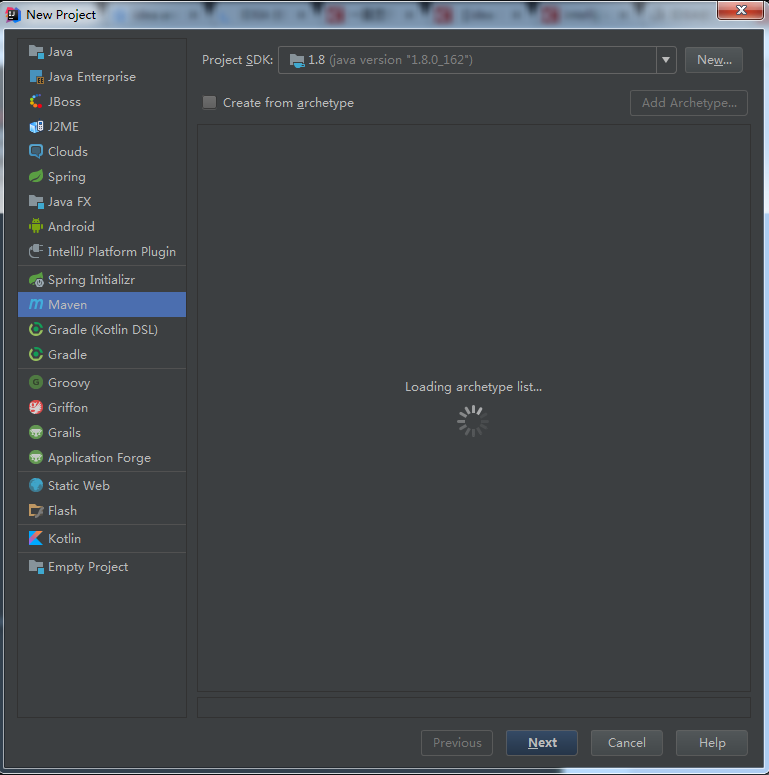
网上搜了一些解决方案:
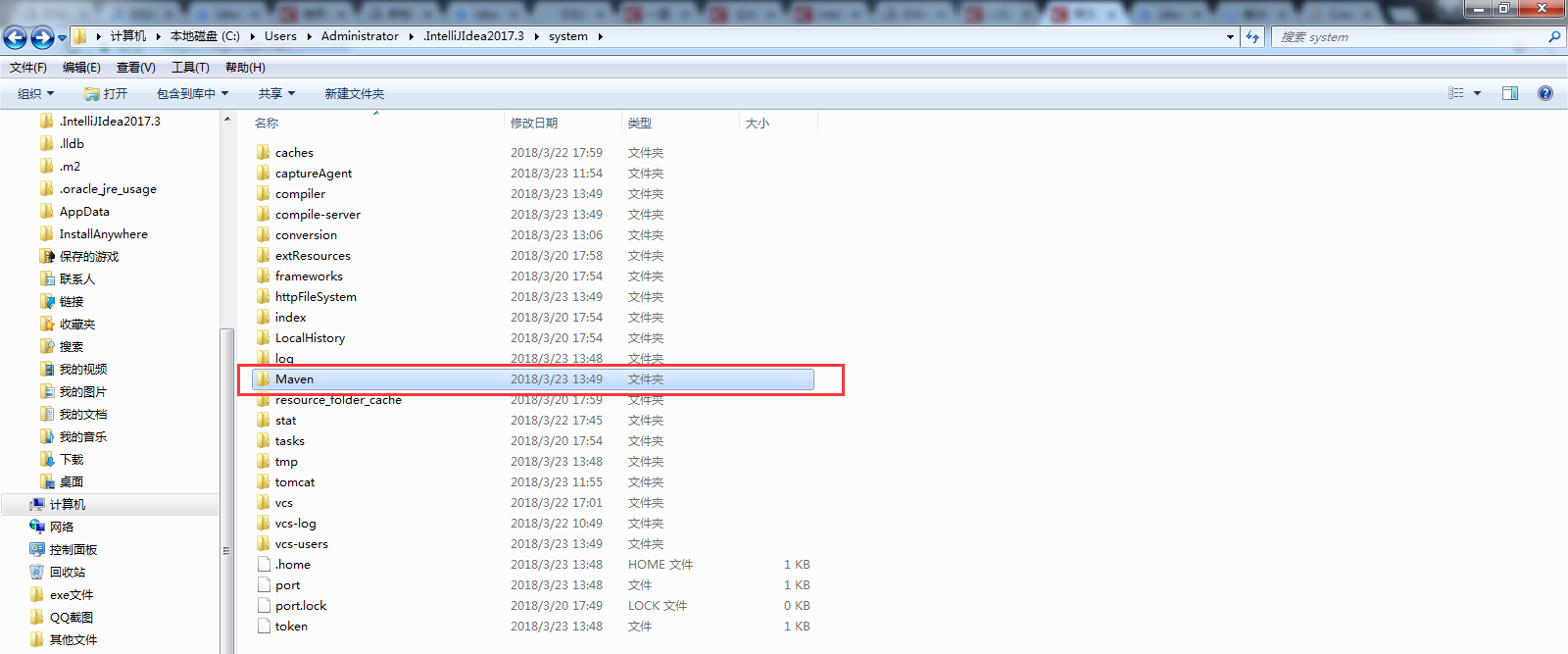
方法一.打开C:\Users\Administrator(具体是自己电脑的用户名)\.IntelliJIdea2017.3(具体是自己的IDEA版本)\system\Maven,把整个文件夹删掉。(这个方法我没有试过,有网友说会产生新的问题)
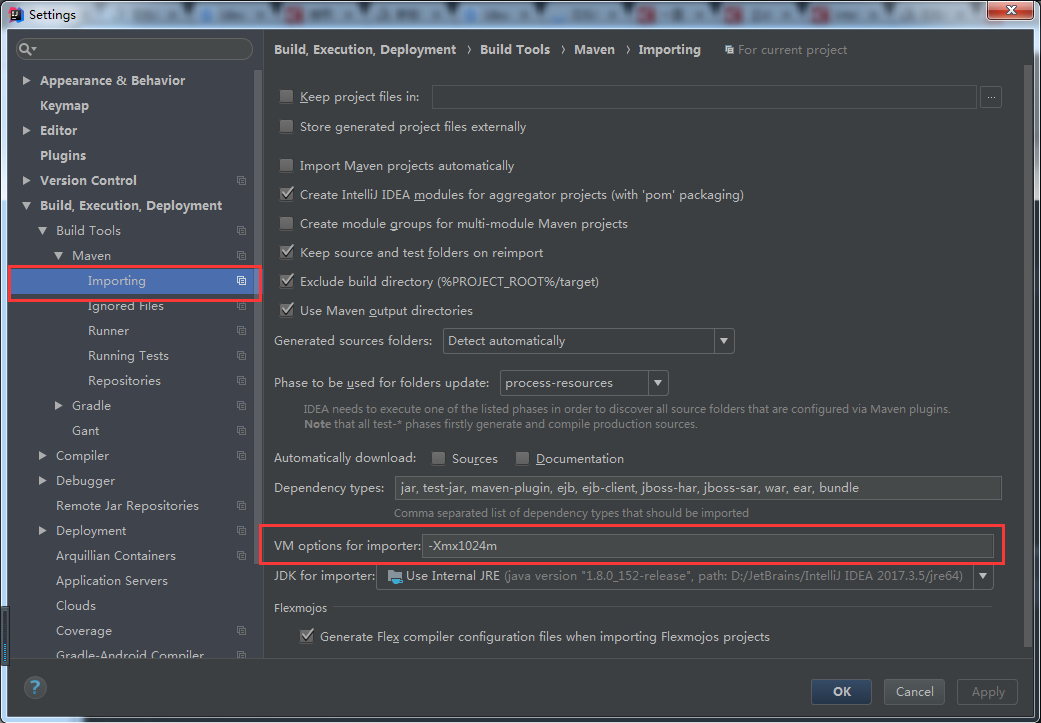
方法二.打开settings,在Build,Execution,Deployment-Build Tools-Maven-Importing的VM-Options for importer修改为:-Xmx1024m,(这个方法我单独试过,貌似没卵用)如下图:
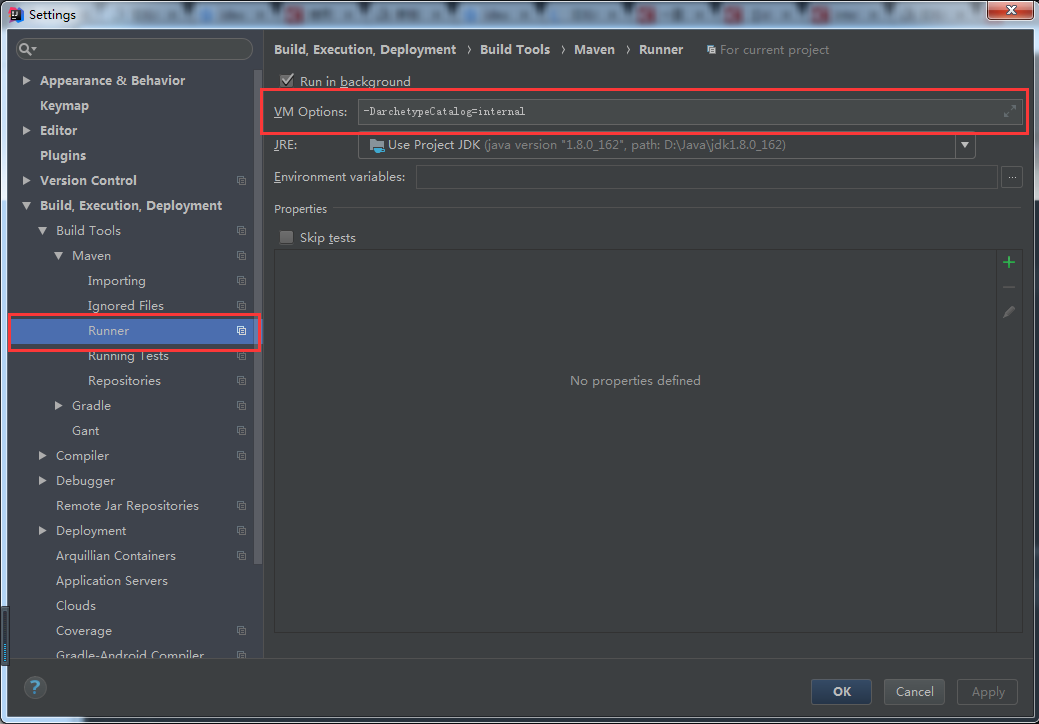
方法三.打开settings,在Build,Execution,Deployment-Build Tools-Maven-Runner的VM-Options加入:
-DarchetypeCatalog=internal。(这个方法我也单独试过,貌似也没卵用)如下图:
方法四.打开C:\Users\Administrator(具体是自己电脑的用户名)\.IntelliJIdea2017.3(具体是自己的IDEA版本)\system\Maven\Indices,把这个文件夹删掉。(这个方法我试了,貌似有用)
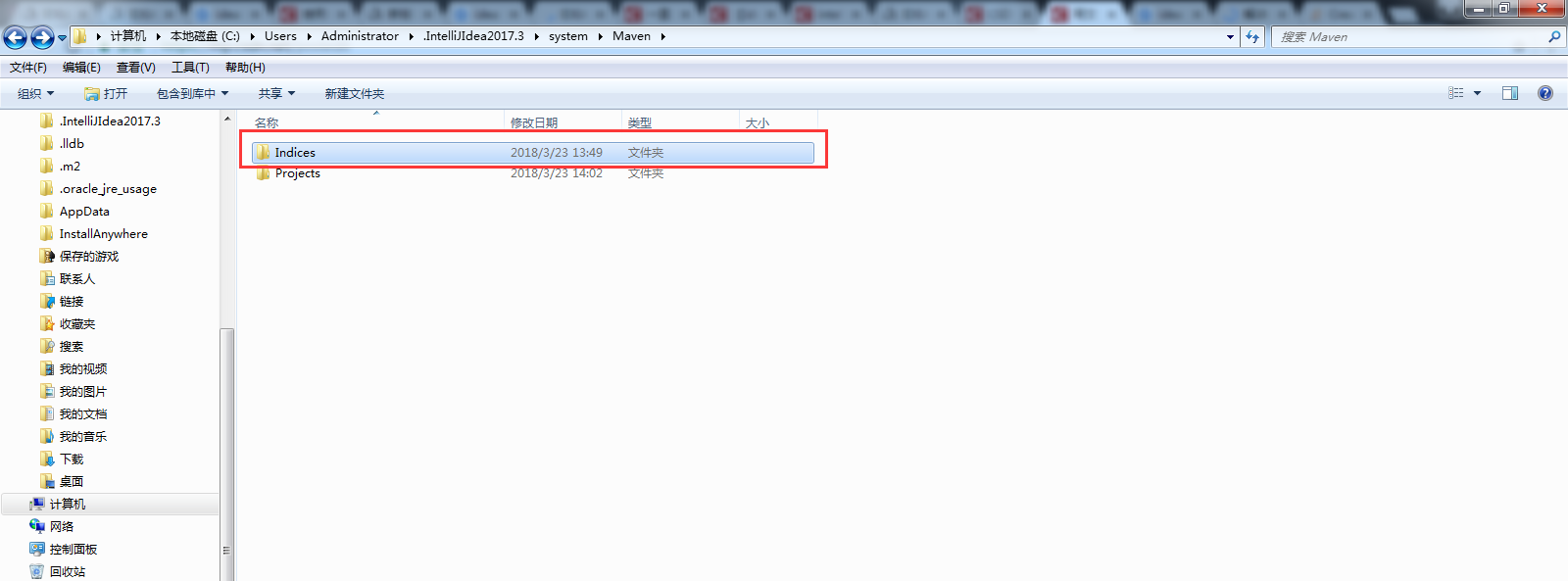
我最后是采用了方法二+方法三+方法四的方式,发现转菊花的情况有所改善,具体是哪一个方法起决定作用暂时不清楚,以后会不会产生新的问题暂时未知,有待观察。
你可能感兴趣的文章
Hive 的文件存储格式怎么选择?
查看>>
Hive 的数据压缩格式怎么选择?
查看>>
Hive 的 SerDe 是什么?
查看>>
Hive 中如何解决多字符分割场景?
查看>>
一篇文章搞懂 Hive 的调优思路
查看>>
HBase是什么?有什么特点?
查看>>
HBase 和 RDBMS 相比有什么区别?
查看>>
一篇文章搞懂 HBase 的整体架构
查看>>
HBase 表的数据模型是什么?
查看>>
3 张图搞懂 HBase 的存储原理.md
查看>>
一篇文章搞懂 HBase 的 flush 机制和 compact 机制
查看>>
一篇文章搞懂 HBase 的 region 拆分机制
查看>>
HBase 表的预分区是什么?为什么要预分区?如何预分区?
查看>>
Flume 是什么?Flume 有什么特点?
查看>>
一篇文章搞懂 Flume 的架构设计
查看>>
Flume 是怎么保障可靠性的?
查看>>
Flume 怎样实现数据的断点续传?
查看>>
Flume 如何自定义 Mysql Source?
查看>>
Flume 如何自定义 Mysql Sink?
查看>>
Flume 的可靠性级别有哪些?
查看>>